Enterprise Web Crawling
Crawl millions of pages with our distributed infrastructure. Handle complex site structures, respect robots.txt, and extract data at scale with enterprise-grade reliability and compliance.
Powerful Features
Enterprise-grade capabilities built for your needs
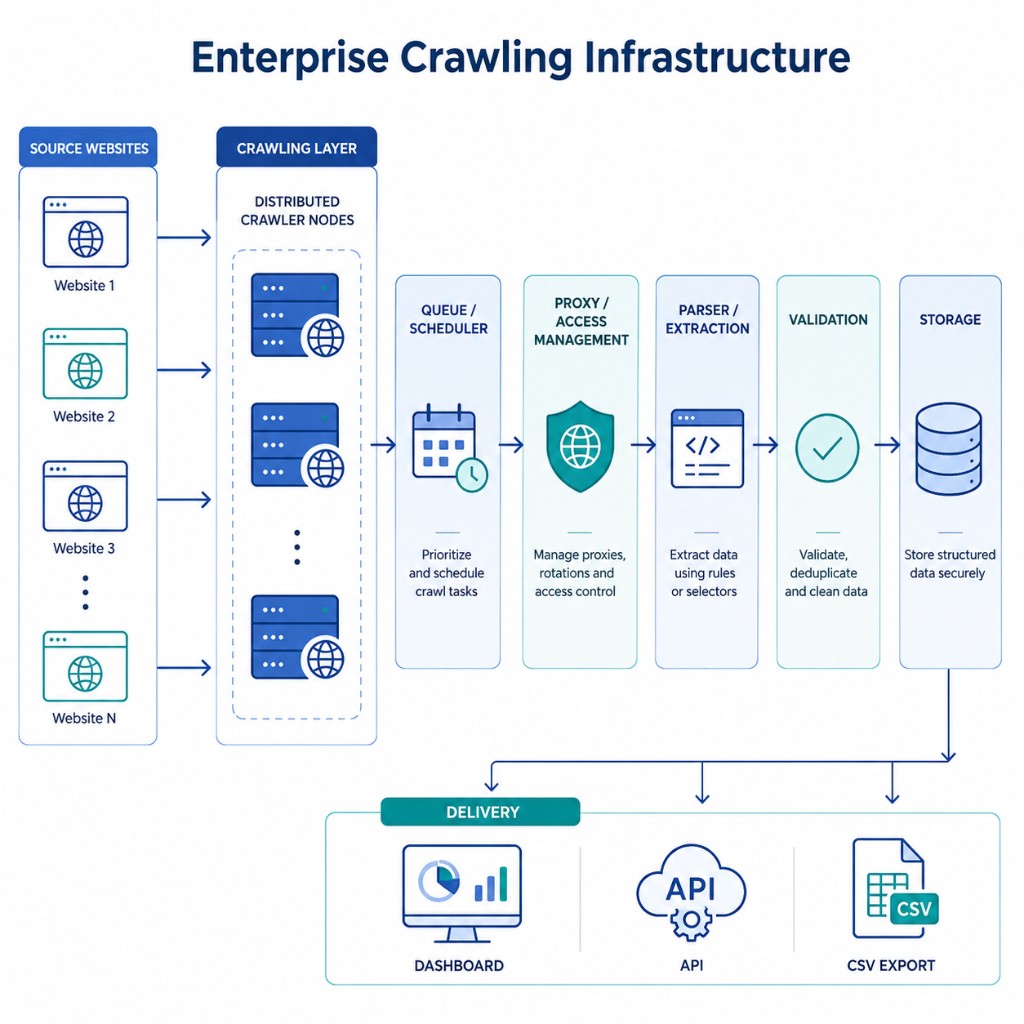
Distributed Architecture
Scalable infrastructure with thousands of servers worldwide for maximum speed and reliability.
Intelligent Rate Limiting
Respect server capacity with smart throttling, polite crawling, and robots.txt compliance.
Secure & Compliant
Enterprise security with data encryption, access controls, and full GDPR/CCPA compliance.
Everything You Need
Real-World Use Cases
See how businesses leverage this solution
Search Engine & Directory Building
Crawl the web to build comprehensive databases for search engines, business directories, or data aggregation platforms.
Market Intelligence
Monitor thousands of websites for news, announcements, and changes relevant to your industry or competitors.
Content Aggregation
Build content platforms by crawling and aggregating articles, listings, or user-generated content from multiple sources.
Compliance Monitoring
Crawl regulated websites to ensure compliance, detect violations, and maintain audit trails for legal requirements.
How It Works
From setup to data delivery in simple steps
Define Crawl Scope
Specify which domains, URL patterns, and content types to crawl. Set depth, frequency, and data extraction rules.
Distributed Crawling
Our infrastructure crawls your targets using thousands of servers, respecting rate limits and handling errors automatically.
Data Delivery
Extracted data is cleaned, deduplicated, and delivered to your systems in real-time or on schedule.
Ready to automate your data?
Tell us what you need. We'll build a custom scraping solution and deliver a free proof-of-concept within 48 hours.